


Everyone remembers the scene. Neo sits in the chair, a cable jacked into the base of his skull, and ten seconds later opens his eyes. “I know kung fu.” That was 2023 for most of us. You typed a question into ChatGPT and it answered like a person. Wonder. The feeling that the ceiling had just moved.
That phase is ending.
What’s happening now is closer to the end of the first film. Neo stops downloading skills and starts seeing the system itself. Not learning more. Seeing differently. The gap between experimentation and orchestration is widening fast, and it’s worth understanding why.
This week I built a revenue engine by connecting Google’s APIs for AdSense, Search Console, and Analytics to a team of AI agents. On the surface, not wildly different from existing dashboard products.
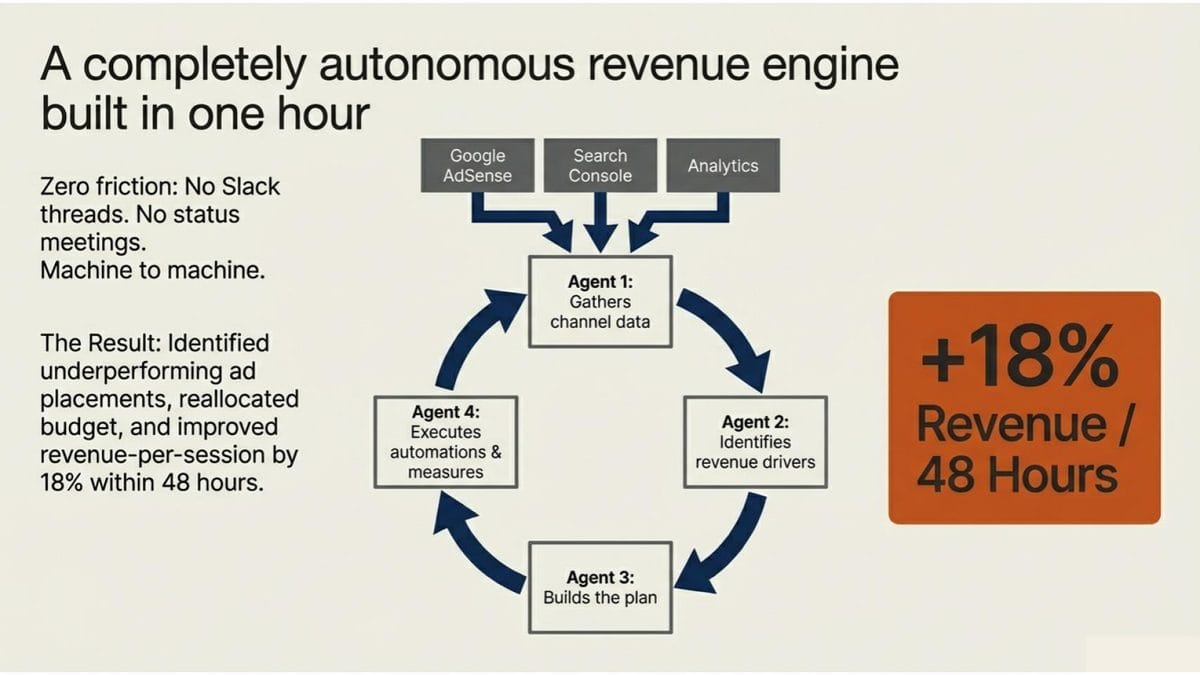
But here’s what changed. The agents don’t just display data. They interrogate it. They talk to each other about it. One gathers performance data across channels, another identifies what’s actually driving revenue, a third builds a plan, and a fourth executes automations and measures results. A dashboard that would have taken a developer days to scope was running in under an hour. In a limited initial deployment, the system identified underperforming ad placements, reallocated budget, and improved revenue-per-session by 18% within 48 hours.
No Slack thread. No status meeting. No “can you send me that deck.” Machine to machine.
- The models didn’t just get smarter. They got conversational. Agents hold context, negotiate tasks, and coordinate like a tight ops team. Except they don’t lose momentum between handoffs.
- This isn’t automation. Automation follows a script. This is orchestration. The agents make judgment calls about sequencing and prioritization in real time.
- What disappeared wasn’t the people. It was the friction between people. The emails, the waiting, the “blocked on so and so” that quietly kills velocity in every organization I’ve ever worked with.
The shift isn’t from human to machine. It’s from prompting to orchestration.

Orchestration is a design problem, not a technical one. It asks the same questions good leaders have always asked: what’s the workflow, where are the dependencies, who owns the outcome.
If you’re someone who runs teams, who sees systems, who understands how work actually flows through an organization, you already have the instincts for this. That’s not flattery. It’s the observation that keeps proving itself out.
The machines learned to talk to each other. The question is who’s going to design what they talk about.
What’s actually happening to software
The week I was building that revenue engine, the broader software market was repricing the entire sector.
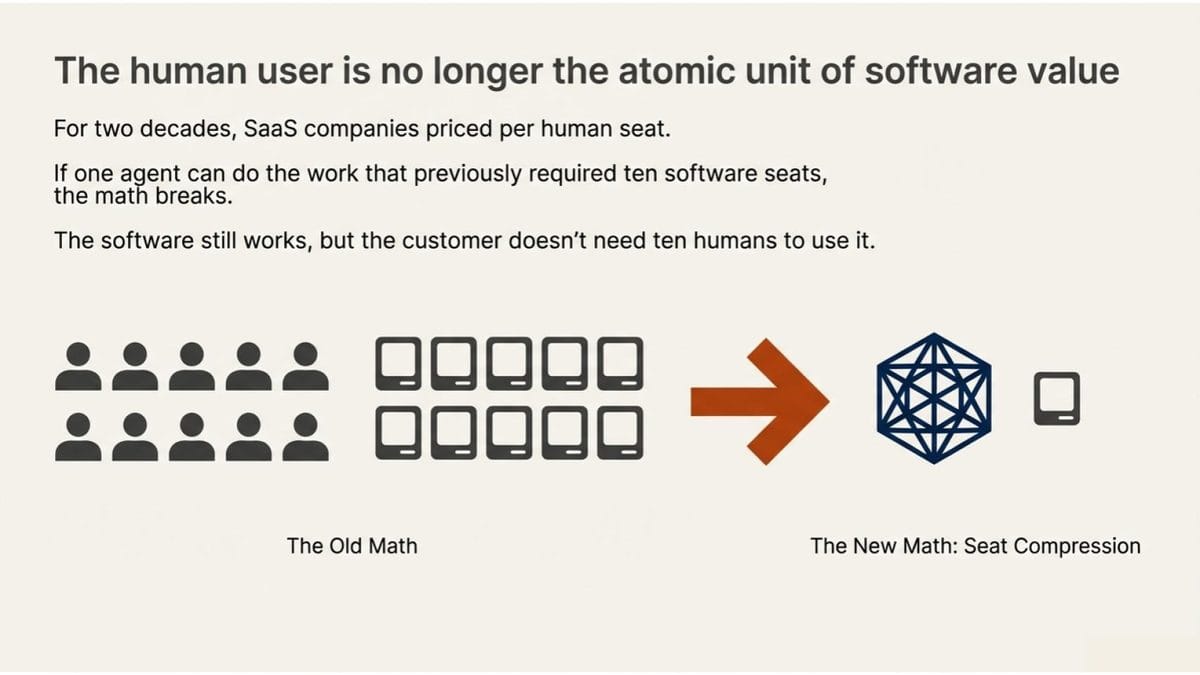
The market has started calling it the SaaSpocalypse. For two decades, SaaS companies priced their software per seat. More humans using the tool meant more revenue. The entire business model assumed that software serves people, and people pay for the privilege.
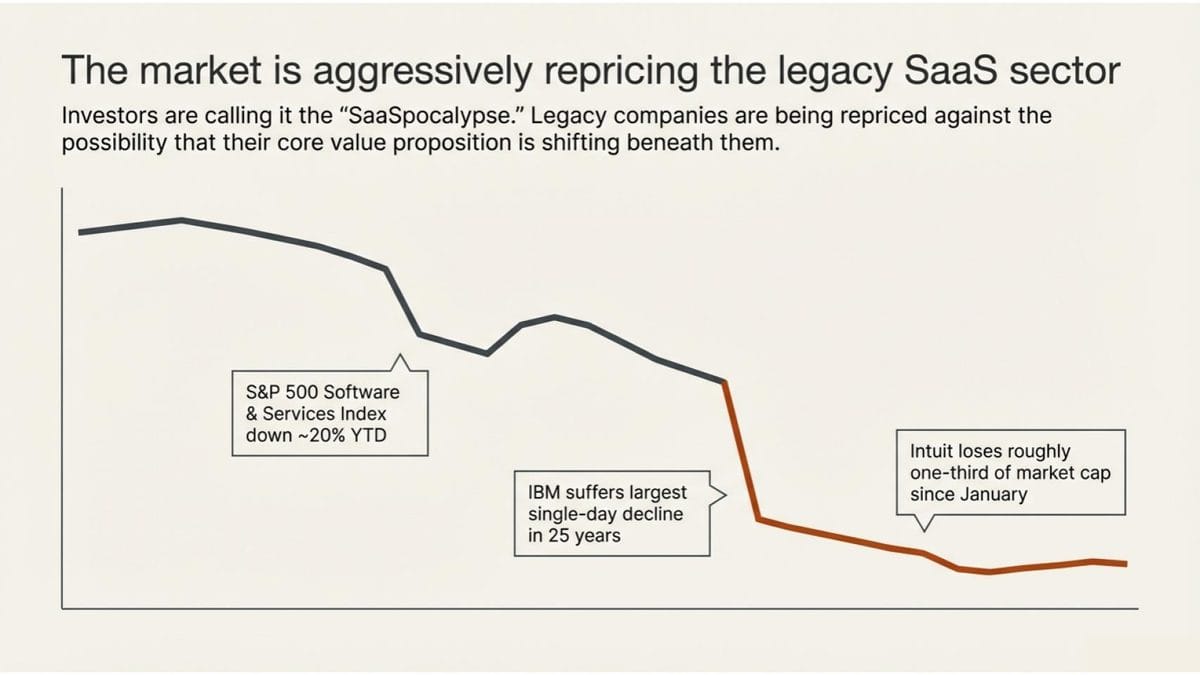
AI agents are beginning to stress that assumption at a structural level. If one agent can do the work that previously required ten software seats, the math changes. Not because the software stopped working, but because the customer doesn’t need ten humans to use it anymore. Investors are calling it “seat compression,” and it’s appearing in earnings calls across the sector. The S&P 500 Software & Services Index is down roughly 20% year to date [1]. Intuit, Adobe, Salesforce, IBM, Atlassian, and Workday have all taken significant hits.
IBM’s largest single-day decline in over 25 years coincided with Anthropic’s announcement that Claude Code could modernize COBOL, the programming language that still underpins the majority of ATM transactions in the U.S. [2]. Intuit has lost about a third of its market cap since January [3]. The pattern across the sector is consistent: legacy software companies are being repriced against the possibility that their core value proposition is shifting beneath them.
But the stock price story obscures something more structural.
The case for the incumbents
Before going further, I want to sit with a counterargument that deserves real engagement.
Alexander Atzberger, CEO of Optimizely, posted a sharp contrarian take a few days ago. I’ve been an Optimizely MVP for five years, so I know the company, and I know Alexander doesn’t hand-wave at disruption. He built a startup within Optimizely with its own P&L specifically to respond to the AI shift.
His argument: most public SaaS companies will improve growth and earnings over the coming quarters. The near-term data supports him. Figma grew revenue 40% last quarter. HubSpot grew 20% and expanded margins.
- Brand, distribution, and enterprise inertia are real forces. Companies don’t change how they buy in weeks. And the AI labs themselves are hiring enterprise sales teams, starting to look like the incumbents they’re disrupting.
- SaaS companies are not standing still. ServiceNow built an AI Control Tower. Atlassian has Rovo. Docusign launched AIM.
- Budgets for AI tools are tapping headcount budgets, not software budgets. The total addressable market may actually be expanding.
I think Alexander is right about most of this. But company survival is not the same thing as customer leverage. The moves these companies are making to survive are also reshaping who controls what. That shift will affect every organization that depends on these platforms long after the stock prices recover.
The moat question
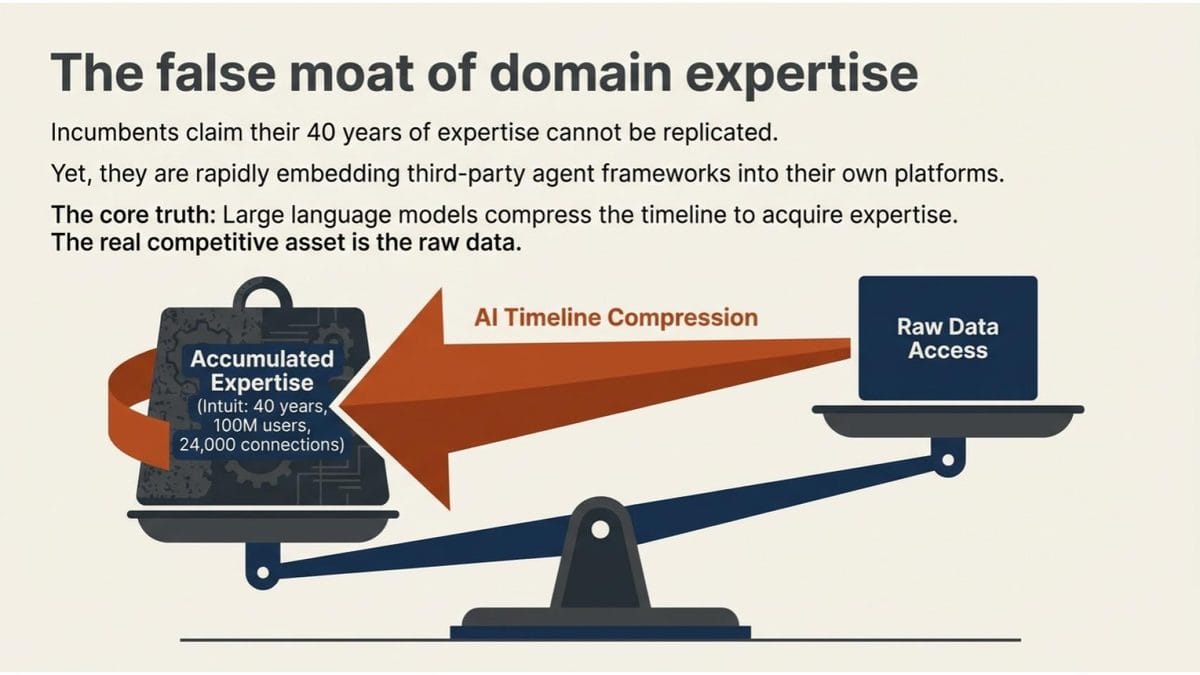
When legacy software companies respond to this pressure, they almost all point to their data. VentureBeat published a piece this week on Intuit. The company’s EVP pointed to first-party customer data from 100 million users, connections to over 24,000 financial institutions, and four decades of domain expertise [3].
You hear versions of this from Adobe about creative workflows, from Salesforce about customer relationships, from IBM about mainframe infrastructure. The pitch is consistent: we have the data, we understand the domain, a general-purpose AI can’t replicate that.
This argument isn’t wrong. But it’s incomplete. The same week Intuit was making its data moat case, the company announced a multi-year partnership with Anthropic to embed Claude’s Agent SDK directly into its platform [4]. Adobe has transitioned to a “Generative Credit” system. Salesforce introduced “Agent Work Units.” HubSpot shifted to credit-based billing tied to agent output.
Every one of these companies is simultaneously arguing that their domain expertise is irreplaceable AND restructuring their business to accommodate the AI frameworks that challenge that claim. That’s not hypocrisy. It’s survival math.
Expertise vs. access
Here’s the distinction that keeps surfacing in every conversation I have with leaders working through this shift: domain expertise and data access are related, but they are not the same thing.
When a company says “we have 40 years of expertise,” they’re describing accumulated pattern recognition. How seasonal cash flow works. What payroll errors look like. Which edge cases trigger audits. That knowledge is real. It was built by thousands of people over decades.
Large language models amplify whoever controls structured domain data. Feed a model decades of financial data and customer behavior, and it will learn patterns at a speed and scale that narrows the gap with human experts every quarter. Not replacing the judgment. Compressing the timeline to acquire it.
The companies making the expertise argument know this. It’s why they’re all partnering with the AI labs. So the real competitive asset isn’t the expertise. It’s the data the expertise was built on. And the question that matters for every organization using these platforms: who controls access to that data, and for whose benefit?
Your data, their terms
In May 2025, Salesforce changed its Slack API terms of service. The update prohibits bulk export of Slack data through the API, explicitly bans using Slack API data to train large language models, and restricts application distribution to the Slack Marketplace or approved partners [5].
If your company uses Slack, your employees have been generating data on Salesforce’s infrastructure every day. Strategy conversations. Product decisions. Customer issues. That data is your organization’s institutional knowledge in its rawest form. And you can no longer use it to build your own AI tools outside their ecosystem.
Vendors will argue these policies are about security and compliance. In some cases they’re right. Letting third-party models train on private messages creates genuine privacy and liability risks. But multiple analysts arrived at the same alternative reading: these restrictions also protect the platform’s own AI ambitions while limiting what customers can do with data they generated [6].
This pattern isn’t unique to Salesforce. As the value layer shifts from interface to data, companies that control data access gain leverage. The organizations that generated the data find themselves on the other side of terms they didn’t negotiate.
The structural tension
Two arguments are being made by legacy software companies right now, and they sit in tension.
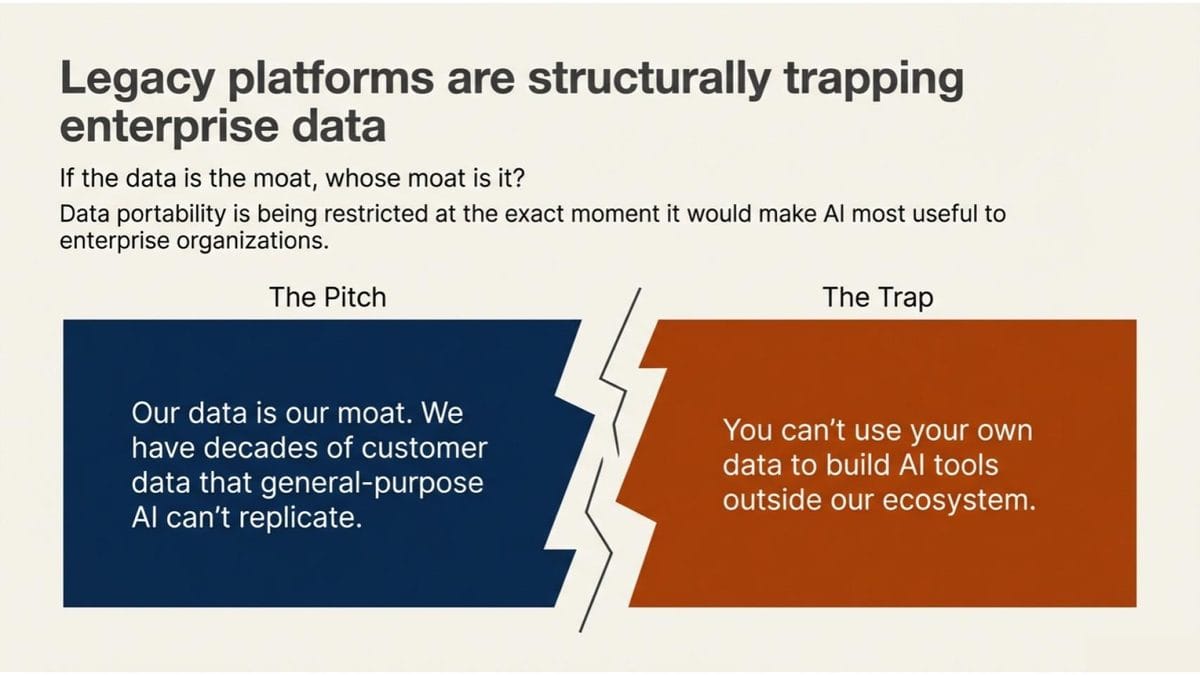
Argument one: our data is our moat. We have decades of customer data that general-purpose AI can’t replicate. This protects us and our customers.
Argument two: you can’t use your own data to build AI tools outside our ecosystem.
- If the data is the moat, whose moat is it? The company that generated the data by doing actual work, or the platform that happened to be the system of record?
- If domain expertise is the differentiator, why embed the general-purpose model’s agent framework directly into your product?
These companies are not acting in bad faith. They’re working through a genuine crisis. The data is the leverage they have. But the structural consequence is worth naming. Data portability is being restricted at the exact moment when data portability is what would make AI most useful to the organizations that need it.
What’s actually being repriced
The SaaSpocalypse framing focuses on stock prices. Stock prices are a lagging indicator of something deeper.
In many categories, the human user is no longer the atomic unit of software value.
That is the structural shift underneath the market correction. It changes how software gets built, priced, and governed.
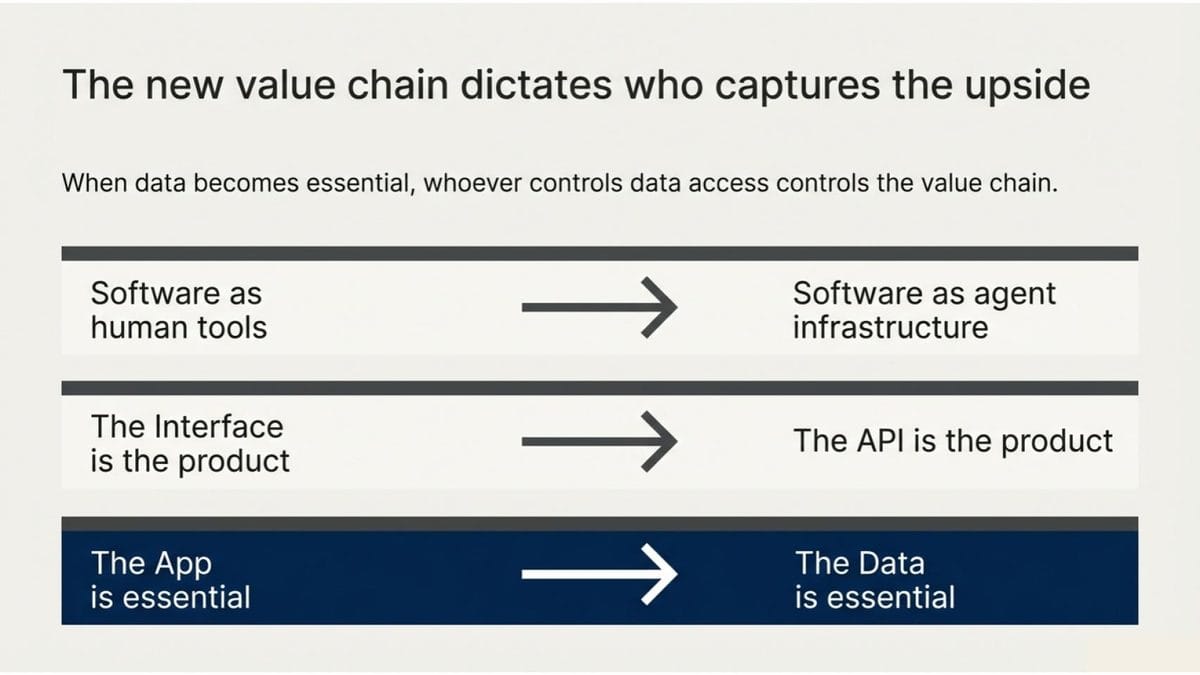
- When software was a tool for humans, the interface was the product.
- When software becomes infrastructure for agents, the API is the product. The interface becomes optional. The data becomes essential.
- When the data becomes essential, whoever controls data access controls the value chain.
This isn’t the only possible future. Regulators could mandate data portability. Open standards could make agent frameworks interoperable. Enterprise customers could demand better terms. And not every organization will want to own its data sovereignty. Many will prefer the convenience of a managed AI stack, and for them, vendor consolidation may feel like relief rather than threat.
But for the organizations that care about leverage, about not waking up one morning to discover that the terms of their most important data relationships changed overnight, the structural momentum favors consolidation of control. Even if incumbents succeed in absorbing AI fully, governance and data access strategy will still determine who captures the upside.
Who owns this
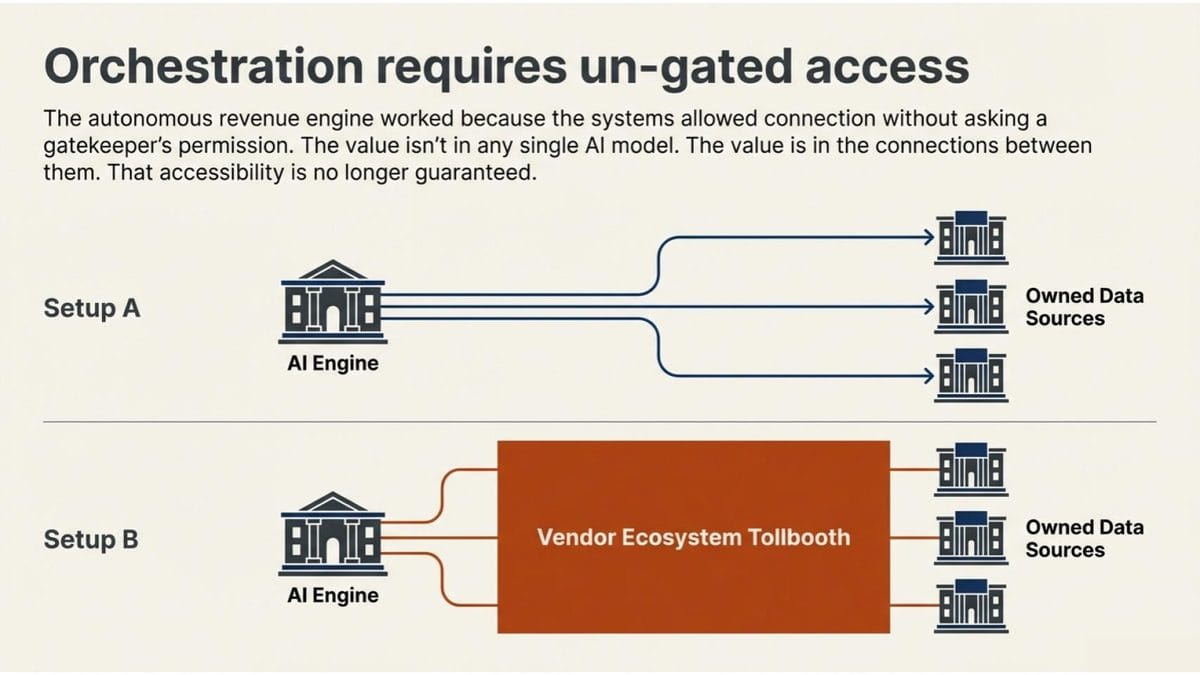
I started this piece talking about a revenue engine. I was able to build it because the tools I used give me access to my own data and let me connect systems without asking a gatekeeper’s permission. The value isn’t in any single model. It’s in the connections between them. That accessibility isn’t guaranteed going forward.
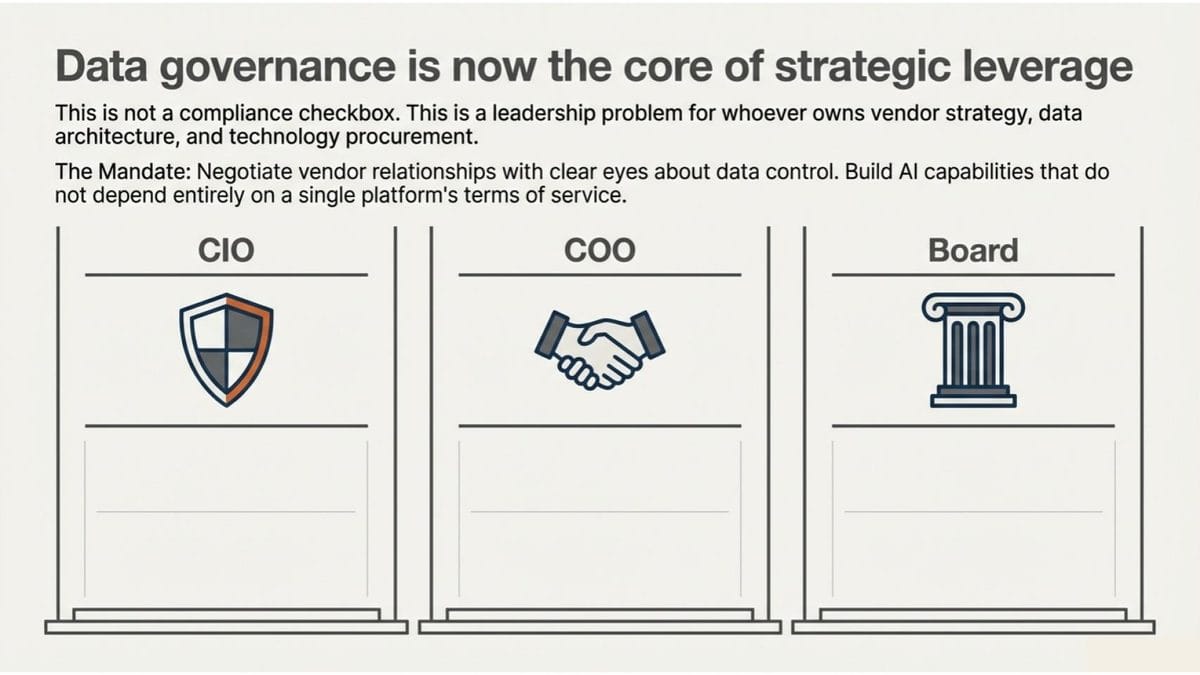
This is a specific leadership problem, and it belongs to whoever owns vendor strategy, data architecture, and technology procurement. In most companies, that’s the CIO, the COO, and increasingly the board itself.
The organizations that handle this well will treat data governance as a strategic discipline, not a compliance checkbox. They’ll negotiate vendor relationships with clear eyes about who controls what. They’ll build AI capabilities that don’t depend entirely on one platform’s terms of service. That’s the work that keeps pulling at me: seeing the structural layer beneath the tool layer, and designing systems that create leverage rather than dependency.
The machines learned to talk to each other. Someone needs to decide what they’re allowed to say.
Sources
- [1] CNBC, “AI fears pummel software stocks,” February 6, 2026
- [2] Bloomberg, IBM share price reporting, February 23, 2026
- [3] VentureBeat, “Intuit is betting its 40 years of small business data can outlast the SaaSpocalypse,” March 2, 2026
- [4] CPA Practice Advisor, “Intuit Partners with Anthropic to Bring AI to Small Business Management,” February 25, 2026
- [5] Slack API Terms of Service, Data Usage section, updated May 29, 2025
- [6] Computerworld, “Salesforce changes Slack API terms to block bulk data access for LLMs,” June 12, 2025